[synergy 요청] linked list 1편

01. Linked List 의 개념은? 🤔
자료구조 수업을 통해 Queue와 Stack에 이어 Linked List를 배웠습니다. Linked List는 아래 그림과 같은 구조입니다.
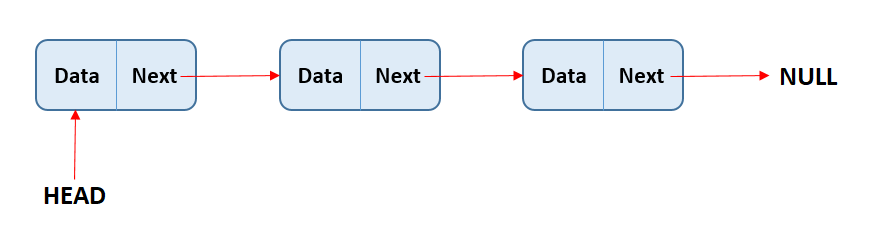
그럼 Linked List의 구조를 좀 더 이해하기 쉽게 배열과 비교해서 설명드리겠습니다.
| 장점 | 단점 | |
|---|---|---|
| Array (배열) | - 각각의 데이터에 접근이 편리하다. | - 배열 중간에 데이터를 삽입하거나 삭제하려면 이후의 데이터들의 구조를 모두 변경해주어야 한다. - 할당받은 공간 내에서만 데이터를 저장할 수 있다. |
| Linked List | - 데이터를 삽입하거나 삭제할 때 전체 구조를 변경하지 않아도 된다. - 연결된 목록은 동적이므로 필요에 따라 늘리거나 줄일 수 있다. |
- List 중간에 있는 데이터에 한 번에 접근이 어렵다. |
Linked List에서 데이터를 삽입하거나 삭제할 때 전체 자료 구조를 변경하지 않아도 된다는 말을 쉽게 그림으로 설명해드리겠습니다. Linked List는 pointer로 다음 데이터를 가르키는 구조이기 때문에 데이터를 중간에 삽입할 때 가르키는 pointer만 변경해주면 됩니다. 아래의 그림과 같습니다.

삭제할 때도 마찬가지입니다. 삭제하려는 데이터를 가르키고 있던 pointer를 다음 데이터를 가르키게 하면 쉽게 삭제할 수 있습니다. 단, 메모리 누수를 방지하기 위해 꼭 메모리 해제를 해주셔야 합니다!

[참조 : Wikipedia]
02. list2 예제 살펴보기! 🤟
간단한 Linked List의 개념을 알아 보았으니 이제 우리가 배운 코드를 해석해보면 어떻게 사용하는지 좀 더 이해가 쉬우리라 생각이 듭니다. 들어가기 전에 해당 예제는 Github (아래 배너에 링크가 있습니다!) - LearningtheCpp - list2에 있는 예제입니다! 충남인력개발원 교육생이 아니신 분들은 예제를 가져와서 함께 확인하셔도 좋습니다.
먼저 코드의 전체적인 구성을 살펴보겠습니다. 내가 아닌 누군가 작성한 코드를 접할 때는 항상 전체적으로 어떻게 코드가 구성되어 있는지 이해하는 것이 중요합니다. 그러기 위해선 먼저 언어에 대한 기본적인 문법을 이해하셔야 합니다. 일단 파일은 3개의 파일로 구성됩니다. 2개의 .cpp 파일과 1개의 .h 파일입니다.
main.cpp
#include <iostream>
#include "list.h"
int main() {
List list1;
list1.insertFirstNode(4);
list1.insertFirstNode(3);
list1.insertFirstNode(1);
list1.insertNode(1, 2);
list1.deleteNode(3);
list2.insertFirstNode(4);
list2.insertFirstNode(2);
list2.insertFirstNode(1);
/// 생략
if (list1 == list2)
std::cout << "list1 and list2 are equal" << std::endl;
else
std::cout << "list1 and list2 are not equal" << std::endl;
return 0;
}
list.h
#ifndef LIST_H
#define LIST_H
class Node {
friend class List;
private:
int data;
Node *next;
Node();
Node(int d, Node *n);
};
class List {
private:
Node *ptr_;
public:
List();
~List();
bool operator==(const List& rhs) const;
void insertFirstNode(int data);
void insertNode(int prevData, int data);
void deleteNode(int data);
};
#endif
list.cpp
#include <iostream>
#include "list.h"
Node::Node(int d, Node *n)
: data(d), next(n) {
}
List::List() {
this->ptr_ = new Node(-1, NULL);
assert(ptr_);
}
List::~List() {
Node *p;
p = ptr_;
while (p ) {
Node* tmp = p;
p = p->next;
delete tmp;
}
}
bool List::operator==(const List& rhs) const {
Node *p = this->ptr_->next;
Node *p2 = rhs.ptr_->next;
while (p ) {
if (p->data != p2->data)
break;
p = p->next;
p2 = p2->next;
}
return (p == NULL);
}
void List::insertFirstNode( int data) {
Node *tmp = new Node(data, ptr_->next);
ptr_->next = tmp;
}
void List::insertNode( int prevData, int data) {
Node* p = ptr_->next;
while (p ) {
if(p->data == prevData)
break;
p = p-> next;
}
if (p ) {
Node *tmp = new Node(data, p->next);
p->next = tmp;
}
}
void List::deleteNode(int data) {
Node* p1 = ptr_->next;
Node* p2 = ptr_;
while(p1 ) {
if (p1->data == data)
break;
p1 = p1->next;
p2 = p2->next;
}
if (p1 ) {
p2->next = p1->next;
delete p1;
}
}
코드가 생각보다 길어 답변에 필요한 일부 코드만 가져왔습니다. (순회 부분은 어떤 말씀이신지 몰라서 정리를 못했습니다.. 혹시 빠진 내용 있으면 아래 댓글 남겨주세요! 설명 추가하겠습니다)
이렇게 코드를 길게 보니 어려워 보이고 전체 구성을 살펴 보라는 말을 이해하기 어려우실텐데요. 그럼 이제부터 저와 함께 하나씩 살펴보도록 하겠습니다.
구성을 살펴 보는 첫번째는 먼저 함수와 class부터 정리해보는 것입니다. 위의 코드를 살펴보면 list.h 파일에 2개의 class가 정의되어 있습니다. 그리고 함수는 main 함수부터 다양한 기능의 함수들이 정의되어 있습니다. 정리하면 아래와 같을 겁니다.
.PNG)
두 개의 class는 저런 모습으로 생겼을 것이라고 정의가 되어 있고, function은 main을 제외하면 각 class의 생성자, 소멸자 외에는 List 클래스에 속해있는 함수 4개가 끝입니다. (참고로 다시 말씀드리자면 답변에 필요한 일부 함수만 가져왔습니다!)
이렇게만 정리해보아도 저렇게 길었던 코드가 간단해졌죠?
두번째는 함수의 인자값과 반환값을 살펴보는 것입니다. 사실 함수의 이름만 보면 함수의 기능을 예측해볼 수 있습니다.
.PNG)
예를 들어 insertNode 함수의 인자값에는 int prevData와 int Data가 있는데 어떻게 사용될 지 생각해보고 함수에 반환값은 void 이므로 반환값 없이 실행만 시키는 함수이구나 라는 것을 파악해보는 것이 필요합니다.
자 이렇게 각 함수의 기능과 인자값, 반환값까지 확인했다면 이제 main 코드부터 한 줄 씩 해석해봅시다.
03. list2 예제 코드 해석 1편! 👀
먼저 main 함수의 첫번째 줄부터 해석을 시작합니다.
int main() {
List list1;
list1.insertFirstNode(4);
list1.insertFirstNode(3);
list1.insertFirstNode(1);
list1.insertNode(1, 2);
list1.deleteNode(3);
list2.insertFirstNode(4);
list2.insertFirstNode(2);
list2.insertFirstNode(1);
/// 생략
if (list1 == list2)
std::cout << "list1 and list2 are equal" << std::endl;
else
std::cout << "list1 and list2 are not equal" << std::endl;
return 0;
}
list1이라는 이름으로 List 클래스 타입을 선언했습니다. class를 생성할 때 인자값을 따로 주지 않았기 때문에 인자값이 없는 생성자 List() 함수가 실행될 것입니다. 현재까지 STACK 영역의 모습은 아래와 같습니다.
.PNG)
생성자의 역할이 끝났으니 STACK 영역의 list() 함수는 종료될 것입니다. 그리고 이어서 list1 class가 insertFirstNode 함수를 호출합니다. 인자값은 4를 주었고 insertFirstNode 함수의 코드는 아래와 같습니다.
void List::insertFirstNode(int data) {
Node *tmp = new Node(data, ptr_->next); //ptr_에는 this->가 앞에 생략됨
ptr_->next = tmp;
}
insertFirstNode 함수의 코드를 살펴보니 tmp라는 Node pointer를 선언합니다. Node *tmp; 까지의 모습은 아래와 같습니다.
.PNG)
여기서 new Node(data, ptr_->next); 코드를 통해 Node(int d, Node *n) 함수가 호출됩니다. 그림은 아래처럼 변합니다.
.PNG)
이렇게 Node 생성자가 종료되면 tmp는 4라는 정수 값과 Null을 가르키는 Node class를 가르키게 됩니다. 여기서 마지막 남은 코드 ptr_->next = tmp; 를 실행합니다.
.PNG)
이렇게 insertFirstNode 함수가 종료되었습니다. 이 작업을 한번 더 반복해보겠습니다. 이번에는 3이라는 인자값을 받아서 insertFirstNode 함수가 호출됩니다.
.PNG)
Node 생성자까지 종료된 모습입니다. 이제 나머지 코드 한 줄이 실행되겠죠?
.PNG)
이렇게 Node의 값은 -1 → 3 → 4 의 순서가 됩니다. 아직까지는 이해가 안되시는 부분들도 많을 거라 예상됩니다. 분명 첫번째 Node에 값을 넣는다고 했는데 4라는 값은 두번째 Node 값에 들어가있습니다. 미리 말씀드리자면 -1이 들어가있는 Node는 이후에 데이터를 삭제하거나 수정할 때를 위한 Dummy Node 입니다. 이 부분은 조금 어려우니 따로 설명을 추가하겠습니다.
일단 여기까지 완료되면 앞으로 insertFirstNode 가 호출되면 어떻게 변할지 예측이 가능하실 겁니다. 다음 코드 list1.insertFirstNode(1); 가 실행되면 -1 → 1 → 3 → 4 이렇게 데이터가 정리될 거라는 거 다들 아시겠죠? 마찬가지로 아래에 있는 Node class 타입의 변수 list2도 insertFirstNode 함수가 종료되면 -1 → 1 → 3 → 4 가 될 것이라고 예측할 수 있습니다.
일단 여기까지 코드의 구성을 확인하고 Node 생성자 함수와 insertFirstNode 함수의 코드까지 살펴봤습니다. 블로그가 길어지는만큼 다음 블로그에서 바로 이어서 정리해보겠습니다. 여기까지 설명이 틀린 부분이나 부족한 부분이 있다면 꼭 아래 댓글로 요청해주세요! 감사합니다. 😄
다음 블로그에 바로 이어서 설명하겠습니다!!! 다들 공부 파이팅하세요!!!
댓글